The Capital One data breach this past August impacted over 100M individuals but provided some important lessons and a few silver linings. With so many affected, the FBI’s quick arrest of the perpetrator was met with relief and questions of what had happened to the data. Although the data had been downloaded and posted privately on Github, the actual data was never sold or disseminated. In fact, much of the highly sensitive data, in particular Social Security and account numbers, had been "tokenized" and therefore remained secure.
Roughly 99% of the Social Security Numbers were protected. But why then were some 140,000 SSNs exposed? As it turns out, those that were exposed had not been tokenized. As per Capital One’s policies, all American SSNs should be and were tokenized. But, Capital One's policies did not require tokenizing the employee ID field, which in some cases consisted of a SSN. Also, the equally sensitive Canadian Insurance Numbers, with a slightly different format than the US numbers, were not tokenized and over 1M were exposed.
Data privacy professionals should note the importance of tokenizing data over encryption. The attacker in this instance gained unauthorized access to the encryption keys, and the encrypted data was then successfully decrypted and breached. Tokenized data, however, remained fully protected.
As illustrated by this incident, the risk of theft or misuse of an encryption key remains a major hurdle to fully securing data with encryption. The bank exposed the most sensitive PII (Personally Identifiable Information) tied to some of its US and Canadian customers when encryption failed to protect the data.
As illustrated by this incident, the risk of theft or misuse of an encryption key remains a major hurdle to fully securing data with encryption. The bank exposed the most sensitive PII (Personally Identifiable Information) tied to some of its US and Canadian customers when encryption failed to protect the data.
Tokenization
Payment vendor Square reports that ‘payment experts are seeing more and more organizations moving from encryption to tokenization as a more cost-effective (and secure) way to protect and safeguard sensitive information.“
The most frequenlty stolen Social Security Number of all time is 078-05-1120. The story behind the stolen SSN dates back to 1938 when Douglas Patterson, VP of E.H. Ferree Company, used his secretary’s real SSN on thousands of example Social Security Cards. The purpose of the fake card with a real number was to demonstrate how well it fit into a new line of wallets. Although the sample card was labeled specimen and printed in red instead of blue, the SSN was eventually used by over 40,000 people, some of whom had thought that the card in their wallet was their own.
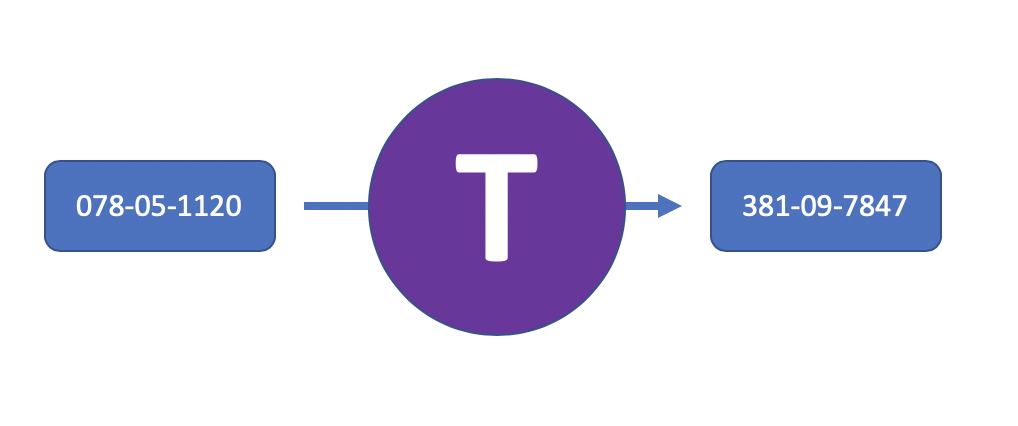
Tokenization can have another benefit. When the format is preserved, and the values are constrained (e.g., digits), the output can be indistinguishable from a real value. In the case of Capital One, it’s unlikely the hacker knew that the SSN values were synthetic, and not real values. According to the FBI, she wrote:

Unknown to the hacker, the SSNs were tokenized, so they were synthetic values unrelated to real Social Security Numbers. Had Capital One also tokenized Canadian Insurance Numbers and employee ID fields, its likely none of these numbers would have been breached
Random Tokenization
Capital One appears to have used a tokenization technique, known as Format Preserving Encryption (FPE), which itself uses encryption. Had these keys, used by FPE, also been stolen, the tokenized data could have been decrypted.
A better approach is random tokenization, whereby, as the term implies, the tokens are selected randomly. Random tokenization uses a separate key-value database or token vault to consistently tokenize the input data. Unlike encryption, random tokenization does not rely on a single set of keys and the tokens are not vulnerable to mathematical or brute force attacks.
As Jonathan Deveaux wrote in Payments Journal: tokenization "can address the failings of encryption” and “if a hacker was successful and gained access to the tokenized data, it would still be protected as the information would have no exploitable value.”
Summary
Tokenization is recognized as a highly effective data protection technique, and the Capital One incident clearly illustrates its value and effectiveness.
Capital One had policies for tokenizing SSN data. Had Capital One simply tokenized more fields with PII data, neither the SSN or CIN numbers would have been breached and their financial exposure, estimated at $100-$150M, would likely be limited. In contrast, encryption as a data protection policy, remains highly vulnerable to theft or mis-use of the necessary encryption keys.
Capital One had policies for tokenizing SSN data. Had Capital One simply tokenized more fields with PII data, neither the SSN or CIN numbers would have been breached and their financial exposure, estimated at $100-$150M, would likely be limited. In contrast, encryption as a data protection policy, remains highly vulnerable to theft or mis-use of the necessary encryption keys.
References
Why Tokenization Is Key When It Comes to Security and Compliance for the Modern PSP, Payments Journal, July 25, 2019
Capital One Hack Explained: What’s in your Bucket?, Peerlyst, July 30, 2019
United States of America vs Paige A Thompson a/k/a “erratic”, US District Court for the Western District of Washington, July 29, 2019